Last updated: May 16, 2026
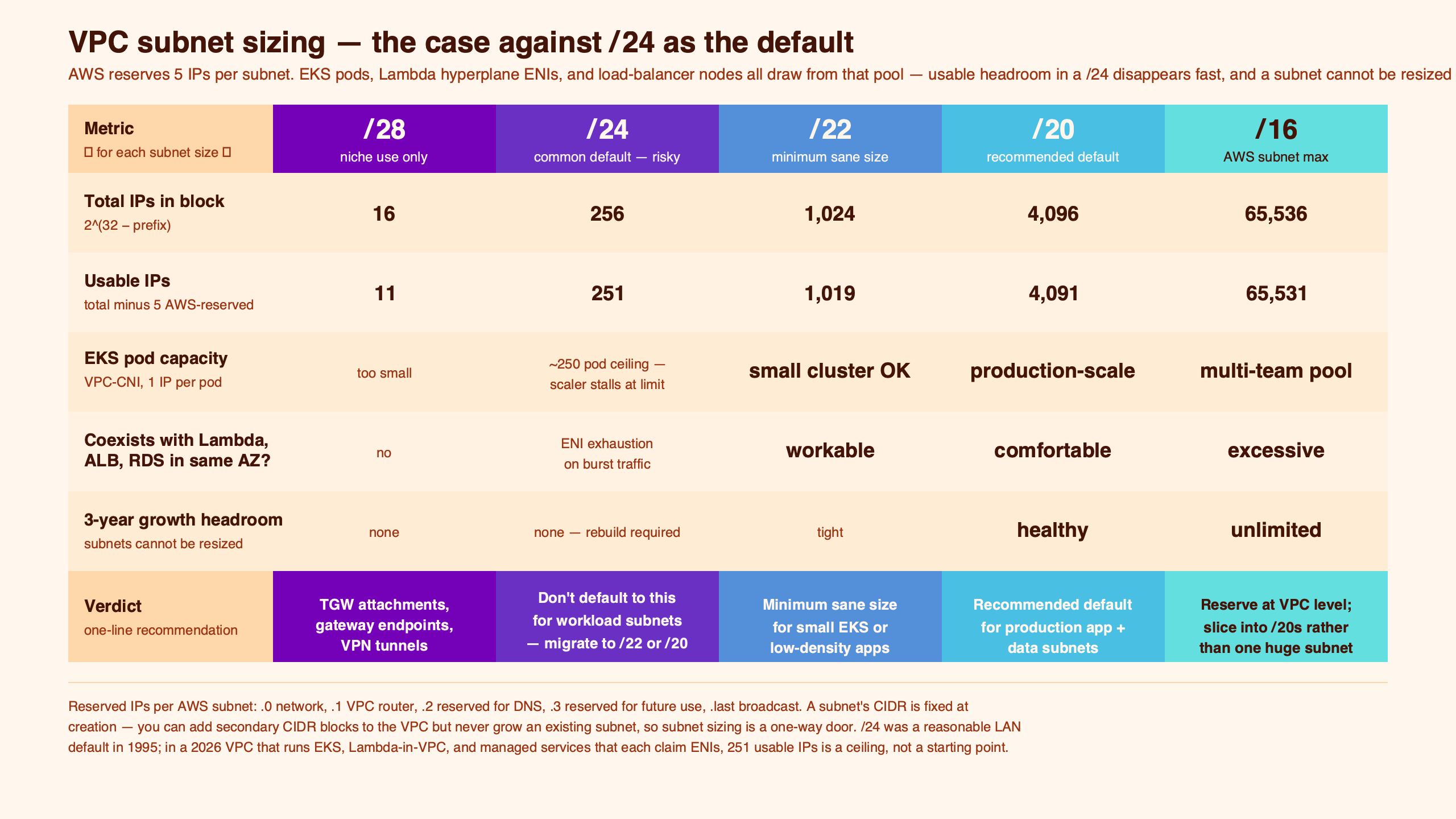
Default to /22 or /20 for new VPC subnets, not /24 — the only test that matters is reversibility, and subnets fail it. Oversize the subnet and AWS bills you exactly nothing for the unused addresses; undersize it and the remediation is a secondary VPC CIDR, a new subnet, and a workload migration. AWS’s own default VPC ships /20 subnets per Availability Zone, not /24, which should already settle the convention.

Default to /22 or /20 for new VPC subnets, not /24 — the only test that matters is reversibility, and subnets fail it.
- AWS reserves 5 IP addresses per subnet, so a /24 yields 251 usable addresses, not 256.
- The default VPC AWS hands every new account uses /20 subnets per AZ, not /24.
- EKS with the AWS VPC CNI assigns one VPC IP per pod; a /24 caps a single AZ near 250 pods minus other infrastructure.
- Subnet CIDR blocks are immutable after creation — you cannot grow a /24 into a /22 in place.
- Allocated-but-unused IPs cost nothing on the AWS bill. Oversizing is free; undersizing is a migration.
The /24 default is a class-C reflex, not a design decision
The /24 default survives because /24 was the size of a class C network in the pre-CIDR Internet and because 256 is a round number that fits in a single octet. Neither is a reason to pick it for a cloud VPC subnet today. AWS itself doesn’t use /24 as a default: when you create a default VPC, you get a /16 with one /20 subnet per AZ — a configuration that hands you roughly 4,091 usable addresses per AZ rather than 251.
The convention persists in tutorials, Terraform modules, and team runbooks because it looks tidy on a whiteboard. It survives review because nobody wants to sound paranoid asking for more address space, and because reviewers can do the math in their head. But the math is the wrong math: it counts addresses, when the constraint that actually bites is interface density over the lifetime of the workload.
See also subnet sizing fundamentals.
The AWS documentation pages for default VPC components show the pattern AWS chose for itself — /16 VPC, /20 subnets, one per AZ. Treat that as the implicit recommendation. If the team running the platform doesn’t trust /24 for its own defaults, copying /24 into your custom VPC is a worse decision, not a more conservative one.
Why subnet sizing is asymmetric: oversizing is free, undersizing is a migration
The two failure modes are not equal. Oversizing a subnet costs nothing. AWS does not bill per allocated IP address inside a VPC. A /20 with three running EC2 instances has the same monthly cost as a /28 with three running EC2 instances. The only cap that matters is the size of the VPC: the IPv4 address space reserved at VPC creation, not the slices you carve from it.
Undersizing is a forklift migration. The AWS VPC CIDR blocks documentation states explicitly that you cannot increase or decrease the size of an existing CIDR block. Subnets are immutable in the same way. When a /24 fills up, the remediation is: associate a secondary VPC CIDR, create new subnets in it, update route tables, redeploy workloads onto the new subnets, then delete the old subnet once it’s empty. That is a multi-week project for any non-trivial service, and it happens while production is running.
Background on this in designing for growth headroom.
Asymmetric cost is the heart of the decision. When one outcome is free and the other is a migration, you don’t pick the middle; you pick the cheaper failure.
What actually consumes IPs in a modern VPC subnet
The AWS VPC FAQ enumerates the network objects that live inside a subnet without ever counting them. The count is what matters. Each of these claims at least one IP from the subnet’s pool:
- AWS reserves 5 addresses at the start of every subnet for network, VPC router, DNS, future use, and broadcast — see the VPC subnet sizing reference.
- An Application Load Balancer needs one ENI per AZ it serves — three IPs across three AZs, scaling out as traffic grows.
- Each NAT gateway is one ENI in its AZ.
- Each interface VPC endpoint (PrivateLink) is one ENI per AZ it is enabled in. Three endpoints across three AZs is nine ENIs.
- Every EKS pod scheduled by the AWS VPC CNI gets a VPC IP — covered in the EKS best-practices guide on IP address utilization.
- Fargate tasks each claim a dedicated ENI, so IP consumption scales linearly with concurrent task count.
- Lambda-in-VPC uses shared Hyperplane ENIs created per unique subnet/security-group combination. IP consumption scales with the number of distinct (subnet, SG-set) pairs in use, not with concurrent invocations — a single Hyperplane ENI fronts a large amount of concurrency for any function attached to the same subnet/SG combo.
The diagram lays the consumers side by side so the arithmetic stops being surprising. None of these are exotic services; they are the standard furniture of any production VPC. The trap is that they get set up once, never counted, and then the autoscaler hits the wall during the first organic traffic spike.
Related: how ARP scopes broadcast domains.
The IP budget that breaks a /24: a worked example across 3 AZs
Take a boringly typical three-tier app on EKS across three AZs. One AZ has:
- ALB ENI: 1
- NAT gateway: 1
- RDS Multi-AZ primary: 1
- 3 interface endpoints (ecr.api, ecr.dkr, logs): 3
- EKS node ENIs (3 nodes × 2 secondary ENIs each): 6
- 30-pod deployment via VPC CNI: 30
That is 42 IPs in one AZ before any scaling event. A /24 has 251 usable. Comfortable, right? Now turn the HPA up to 200 pods and add a second deployment of 100 pods. The AWS VPC CNI pre-allocates IP prefixes per ENI for warm starts, so individual ENIs can fail to allocate even while the subnet still shows free addresses. That nuance is documented in the AWS containers blog on optimizing pod IP usage.
Background on this in DHCP reservation behavior.
A /22 has 1,019 usable. A /20 has 4,091. The same architecture in a /20 subnet does not think about IPs for years. The same architecture in a /24 starts paging on-call the first time marketing runs a campaign.
A workload-to-prefix decision rubric
Pick the prefix by workload class, not by aesthetic preference. The asymmetric-cost argument means the rubric leans heavy on every row where IP demand scales with traffic.
| Workload | Prefix | Usable IPs | Why |
|---|---|---|---|
| EKS data plane (VPC CNI, default mode) | /20 | 4,091 | One IP per pod; scaling events are bursty and large. |
| Fargate tasks | /20 | 4,091 | Each running task claims a dedicated ENI; concurrency drives the count. |
| Lambda-in-VPC | /24 to /22 | 251 – 1,019 | Shared Hyperplane ENIs per unique subnet/SG combo; capacity-bounded, but leave headroom for additional SG-sets and per-account ENI growth. |
| General workload tier (EC2, ECS-on-EC2, ASG) | /22 | 1,019 | Headroom for ALBs, scaling, blue/green deployments. |
| RDS / data tier | /24 | 251 | Bounded by Multi-AZ instance count plus read replicas. |
| VPC interface endpoints | /26 or /27 | 59 / 27 | One ENI per endpoint per AZ; capacity-bounded. |
| Bastion / jump host | /28 | 11 | Capacity-bounded by definition. |
Source: Usable-IP figures from AWS’s reserved-address rule (5 per subnet); workload mapping derived from the IP-consumption inventory above.
More detail in overlay networking primer.
| Workload class | /25 (123 IPs) | /24 (251 IPs) | /22 (1,019 IPs) | /20 (4,091 IPs) |
|---|---|---|---|---|
| EKS data plane (VPC CNI) | On-call | On-call | Tight | Comfortable |
| Fargate tasks | On-call | On-call | Tight | Comfortable |
| General EC2 / ASG tier | Tight | Tight | Comfortable | Comfortable |
| Lambda-in-VPC (few SG combos) | Tight | Comfortable | Comfortable | Comfortable |
| RDS / data tier | Comfortable | Comfortable | Comfortable | Comfortable (wasteful) |
| Interface endpoints | Comfortable | Comfortable | Comfortable (wasteful) | Comfortable (wasteful) |
| Bastion / management | Comfortable | Comfortable | Comfortable (wasteful) | Comfortable (wasteful) |
The matrix shows the same tradeoff the heatmap captured: reading rows for ENI-dense workloads against the /24 and /25 columns shows the predictable burn pattern, while capacity-bounded workloads stay comfortable at every prefix. The cells where workload demand and subnet capacity collide are the cells where on-call gets paged.
When /24 is actually right: the narrow cases
The opinion is not “never use /24.” There are subnets where /24 is correct because the workload is capacity-bounded:
- Interface endpoint subnets. If you isolate PrivateLink endpoints into their own subnets — a defensible pattern for security-group and route-table separation — demand is one ENI per endpoint per AZ. /26 or even /27 is fine; /24 is generous.
- Bastion / management subnets. A two-host SSM bastion fleet does not need 251 addresses. /28 is appropriate.
- Lambda-only subnets. Because Hyperplane ENIs are shared across invocations of any function bound to the same (subnet, SG-set), a /24 typically has more than enough capacity unless you intend to attach many distinct security-group combinations.
- Database subnet groups when the count of RDS instances and read replicas is bounded by the database product, not by traffic.
- Lab or sandbox VPCs with strict workload caps and no production scaling pressure.
The pattern: /24 is right when the workload’s IP demand is bounded by something other than traffic. That excludes any application tier touched by an autoscaler.
If you already chose /24: the secondary-CIDR escape and the 100.64.0.0/10 CGNAT pattern
The remediation when a subnet fills up is the secondary VPC CIDR. AWS allows up to five IPv4 CIDR blocks per VPC by default, with the quota adjustable on request. The standard sequence:
aws ec2 associate-vpc-cidr-block \
--vpc-id vpc-0abc123 \
--cidr-block 100.64.0.0/16
aws ec2 create-subnet \
--vpc-id vpc-0abc123 \
--cidr-block 100.64.0.0/20 \
--availability-zone us-east-1aEKS teams reach for 100.64.0.0/10 because RFC 6598 reserves it for carrier-grade NAT rather than for private enterprise networks, which often reduces RFC 1918 collision risk in corporate peering. It does not eliminate the risk: any subsequent Transit Gateway, Direct Connect, VPN, or partner VPC attachment still requires explicit routing decisions and an overlap review, because partner or upstream carrier networks can carry the same range. AWS’s EKS guidance on custom networking walks through the ENIConfig pattern that lets pods receive IPs from a secondary CIDR while nodes stay on the primary one — useful when nodes must remain reachable from on-prem on RFC 1918 space but pods can live in CGNAT space.
automating CIDR allocation goes into the specifics of this.

The terminal animation walks through associating the secondary CIDR, creating the new subnet, and updating the EKS ENIConfig. What it does not show is the multi-week project of draining the original subnet’s workloads onto the new one. That work is real; budgeting around it is more expensive than choosing /22 on day one.
The strongest counter-argument
The honest objection to “default to /22” is that VPC IPv4 space is finite per account if you peer or share. A /16 VPC holds sixteen /20 subnets or sixty-four /22 subnets. If you run dozens of VPCs connected through Transit Gateway, address coordination across accounts becomes the constraint, and inflated subnets shorten the runway. Teams under that constraint sometimes pick /24 deliberately to fit more VPCs into a coordinated address plan.
The rebuttal: the coordinated address plan is the right place to enforce thrift, not the subnet decision. Allocate each VPC a /20 or /19 from a global IPAM plan; inside that VPC, slice /22 subnets generously because the cost is local to the VPC’s own allocation. AWS IPAM exists precisely to manage the global allocation problem without forcing subnet-level scarcity. If the address-coordination story is “pick small subnets and hope,” IPAM is the fix, not /24.
For accounts that genuinely cannot get more RFC 1918 space, a secondary CIDR drawn from 100.64.0.0/10 is an escape valve large enough to make the objection moot. CGNAT space holds roughly four million addresses and, because RFC 6598 sets it aside for carrier use rather than for enterprise RFC 1918 allocation, it usually has lower collision risk in private peering than further-overloaded 10.0.0.0/8 space. That is a probability claim, not a guarantee: carrier upstreams, third-party SaaS VPCs, and merged-company networks can and do use overlapping ranges, so any new attachment still needs an overlap review and explicit route policy.
Audit your current subnets in five minutes
Before this becomes a fire drill, count what you already have. The reproducible audit is two commands:
aws ec2 describe-subnets \
--query 'Subnets[*].[SubnetId,CidrBlock,AvailabilityZone,AvailableIpAddressCount]' \
--output table
aws ec2 describe-network-interfaces \
--filters "Name=subnet-id,Values=subnet-0abc123" \
--query 'NetworkInterfaces[*].[InterfaceType,Description,PrivateIpAddress]' \
--output table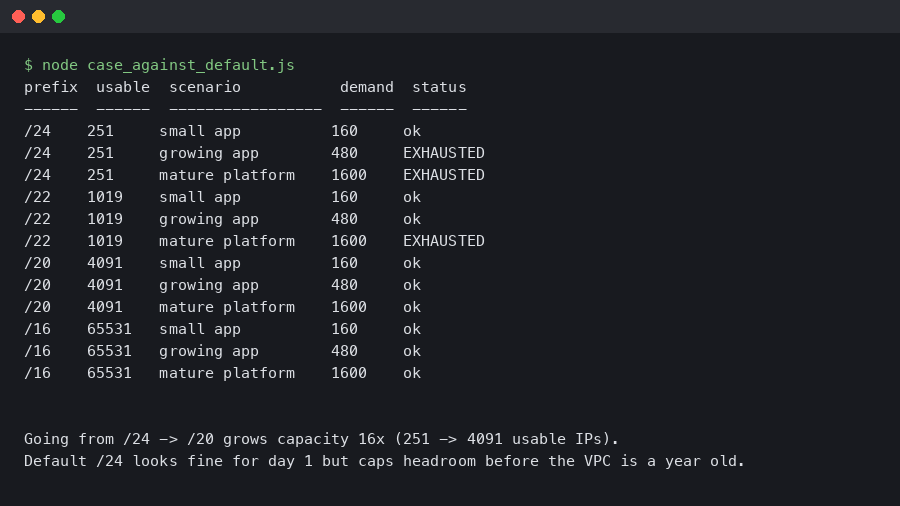
The terminal output shows the AvailableIpAddressCount column dropping across a typical EKS subnet over a workday. Anything below 20% headroom on a workload subnet is a yellow flag; anything below 10% should be on a sprint board, because the next autoscaling event is the one that pages someone. The describe-network-interfaces output tells you what is consuming the addresses — useful for distinguishing “we have 200 pods” from “we leaked 200 ENIs to a misbehaving controller.”
I wrote about socket-level address exhaustion if you want to dig deeper.
Default to /22 for general workload subnets and /20 for any subnet that will host EKS pods or Fargate tasks. Size Lambda-in-VPC subnets by the number of distinct subnet/security-group combinations you expect, not by concurrent invocations. Reserve /24 for purpose-built subnets where IP demand is bounded by something other than traffic. The decision is asymmetric — oversizing is free, undersizing is a migration — and AWS itself uses /20 in the default VPC. Copy that, not the class-C reflex.
References
- AWS VPC user guide: Subnet CIDR blocks — allowed prefix lengths and the five reserved addresses per subnet.
- AWS VPC user guide: Default VPC components — confirms the default VPC uses /20 subnets per AZ.
- AWS VPC user guide: VPC CIDR blocks — CIDR blocks cannot be resized after creation; secondary CIDR is the only path.
- EKS best practices: Optimizing IP address utilization — explains VPC CNI IP-per-pod behavior and prefix delegation.
- AWS containers blog: Optimize IP address usage by pods — covers the failure mode where ENI prefixes exhaust before the subnet does.
- EKS best practices: Custom networking — ENIConfig pattern for routing pods onto a secondary VPC CIDR.
- AWS CLI reference: ec2 describe-network-interfaces — the audit command for enumerating ENIs consuming a subnet.
- RFC 6598 — reserves 100.64.0.0/10 for carrier-grade NAT, the standard escape range for VPC IP exhaustion.