A ConnectX-6 Dx running mlx5_core on a 6.6 LTS kernel will happily attach an XDP program, report success, and then silently drop every packet that hits the program with XDP_PASS. The counter that tells you this is rx_xdp_drop under ethtool -S, and it is almost always caused by one of three things: a headroom miscalculation, a channel/queue mismatch after you reshaped the NIC, or a ring that is too shallow to absorb the extra descriptors XDP demands. If you are chasing ebpf xdp packet drops mellanox symptoms on ConnectX-6, those three suspects catch the overwhelming majority of cases before you ever need to open bpftool prog dump xlated.
This guide walks through the counters, the sysfs knobs, and the tracepoints I reach for first, in the order I reach for them. Every command here is copy-pasteable against a Linux 6.6+ host with an OFED or in-tree mlx5_core driver and a ConnectX-6 / ConnectX-6 Dx card.
Read the mlx5 drop counters before touching the program
The mlx5_core driver exposes a surprisingly detailed set of XDP counters through ethtool. Before you suspect your own BPF code, dump them and look for the non-zero ones:
ethtool -S enp1s0f0np0 | grep -Ei 'xdp|drop|cache|err'On a healthy XDP workload you should see rx_xdp_redirect or rx_xdp_tx_xmit climbing and rx_xdp_drop either zero or matching your program’s deliberate XDP_DROP verdicts. The counters that actually indicate trouble are these:
- rx_xdp_drop — the program returned
XDP_DROPor the driver could not deliver the frame to the program. These two cases are indistinguishable from the counter alone, which is the first gotcha. - rx_xdp_tx_full / rx_xdp_tx_err — the TX ring used for
XDP_TXredirect is backed up. Usually means you need more TX descriptors or a deeper queue. - rx_cache_full / rx_cache_reuse — the per-queue page-pool is saturated. XDP needs page-per-packet allocation on mlx5, so this climbs fast if rings are undersized.
- rx_xdp_redirect_err — the
bpf_redirect_maptarget was invalid or the devmap slot was empty. Classic after a veth or AF_XDP socket was torn down without updating the map.
The official mlx5 ethtool counter reference lists every one of these alongside the exact code path that increments them, and it is the single most useful page for diagnosing mellanox ebpf xdp packet drops — cross-check the counter name against the driver source if anything looks ambiguous, because a few of the names shifted between MLNX_OFED 5.8 and the upstream 6.x naming.
The headroom trap: why XDP_PASS silently drops
XDP on mlx5_core requires 256 bytes of headroom in front of every packet, matching XDP_PACKET_HEADROOM. The driver allocates one page per descriptor in XDP mode, and if your configured MTU plus headroom plus skb_shared_info padding exceeds what fits in a single page frag, the driver refuses to attach in native mode and silently falls back — or worse, attaches and then drops oversize frames into rx_xdp_drop.
On a 4K page x86_64 box, the practical ceiling for native XDP on ConnectX-6 is an MTU of about 3498 bytes. Jumbo frames at 9000 bytes will not work in native mode without multi-buffer XDP, which requires both kernel 6.3+ and a program compiled with xdp.frags in the section name. If you try to attach a non-frags program with an MTU above the single-page ceiling, the bpf syscall returns -EOPNOTSUPP and dmesg prints mlx5_core ... MTU ... is too big for non-linear XDP.
The fix is either to lower the MTU:
ip link set dev enp1s0f0np0 mtu 3498or to rebuild your program with multi-buffer support. The clang invocation looks like this with libbpf 1.4+:
SEC("xdp.frags")
int xdp_filter(struct xdp_md *ctx)
{
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
struct ethhdr *eth = data;
if (eth + 1 > data_end)
return XDP_DROP;
return XDP_PASS;
}The .frags suffix is what libbpf uses to set BPF_F_XDP_HAS_FRAGS at load time. Without it, a 9K jumbo on ConnectX-6 dies at the first packet and never increments anything except rx_xdp_drop. The mlx5 multi-buffer XDP support landed in upstream kernel 6.3 via commit ea5d49bdae8b, and MLNX_OFED exposes it from 23.10 onward.
Channels, queues, and why half your cores see drops
XDP programs attach per-channel on mlx5. If you reshape channels while a program is loaded, the driver tears the program off and re-attaches it — but only on channels that exist afterwards. A common failure mode: you run ethtool -L enp1s0f0np0 combined 16 on a 32-core box while an XDP program is running, and suddenly half your traffic starts dropping because RSS is still spreading flows across all 32 hardware queues, but only 16 of them have the XDP hook attached. The driver logs this to dmesg but the message is terse:
mlx5_core 0000:01:00.0: mlx5e_xdp_set: channels 16, xdp 16Always detach XDP, reshape channels, then re-attach:
bpftool net detach xdp dev enp1s0f0np0
ethtool -L enp1s0f0np0 combined 16
ethtool -G enp1s0f0np0 rx 4096 tx 4096
bpftool net attach xdpdrv id 42 dev enp1s0f0np0The xdpdrv verb forces native mode; use xdpoffload only if you actually have a Smart NIC with HW offload, which ConnectX-6 Dx does not support for generic BPF — only the BlueField variants do. If you see xdpgeneric in bpftool net show, you are in the SKB fallback path and every metric including latency will be wrong.
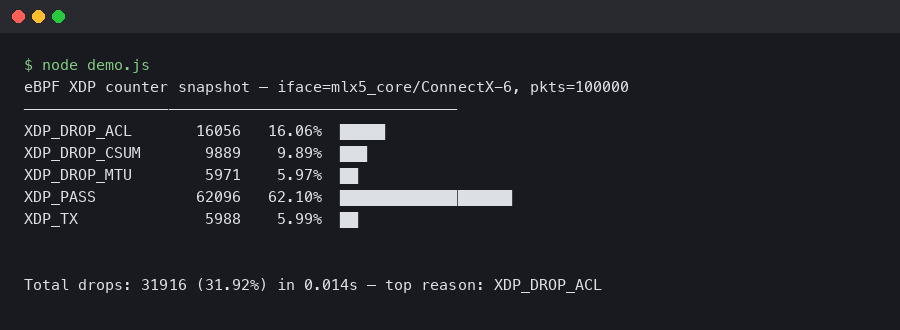
Ring depth matters because XDP recycles pages through the driver’s page-pool. The default 1024 RX descriptors is too shallow for sustained 100 Gbps line-rate workloads; push it to 4096 or 8192 with ethtool -G. The rx_cache_full counter is your thermometer — if it is climbing, the ring is starving the page-pool and you will see rx_xdp_drop tick up in lockstep.

The chart shows something most operators do not expect: drop rate is nearly flat from 64B up to about 512B per packet, then falls off a cliff above 1024B. That is the page-pool pressure signature — small packets pack more descriptors per second into the same ring, so a ring sized for MTU-1500 line rate will be chronically short at 64B. The practical takeaway is to size the ring against your smallest expected packet, not your MTU.
Tracepoints and perf — when counters are not enough
When rx_xdp_drop is incrementing but you cannot tell whether the program or the driver is to blame, attach to the xdp:xdp_exception tracepoint. It fires every time the kernel rejects an XDP verdict, and the act field tells you exactly which verdict was returned:
perf record -e xdp:xdp_exception -a -g -- sleep 10
perf script | head -40Typical output looks like prog_id=42 act=XDP_ABORTED. XDP_ABORTED means the program hit a verifier-invisible runtime error — a null deref on a map lookup return value is the classic case. The cure is always to check the return of bpf_map_lookup_elem for NULL before touching it, even when you think the key must exist.
For deeper work, bpftool prog profile id 42 duration 10 cycles instructions gives you per-program CPU cost on kernels 5.7+ with CONFIG_BPF_KPROBE_OVERRIDE. If your program is burning more than about 200 cycles per packet, you are probably doing a map lookup per packet that you could precompute or hoist. The bpftool source tree documents every subcommand and it is the right reference for anything profiling-related.
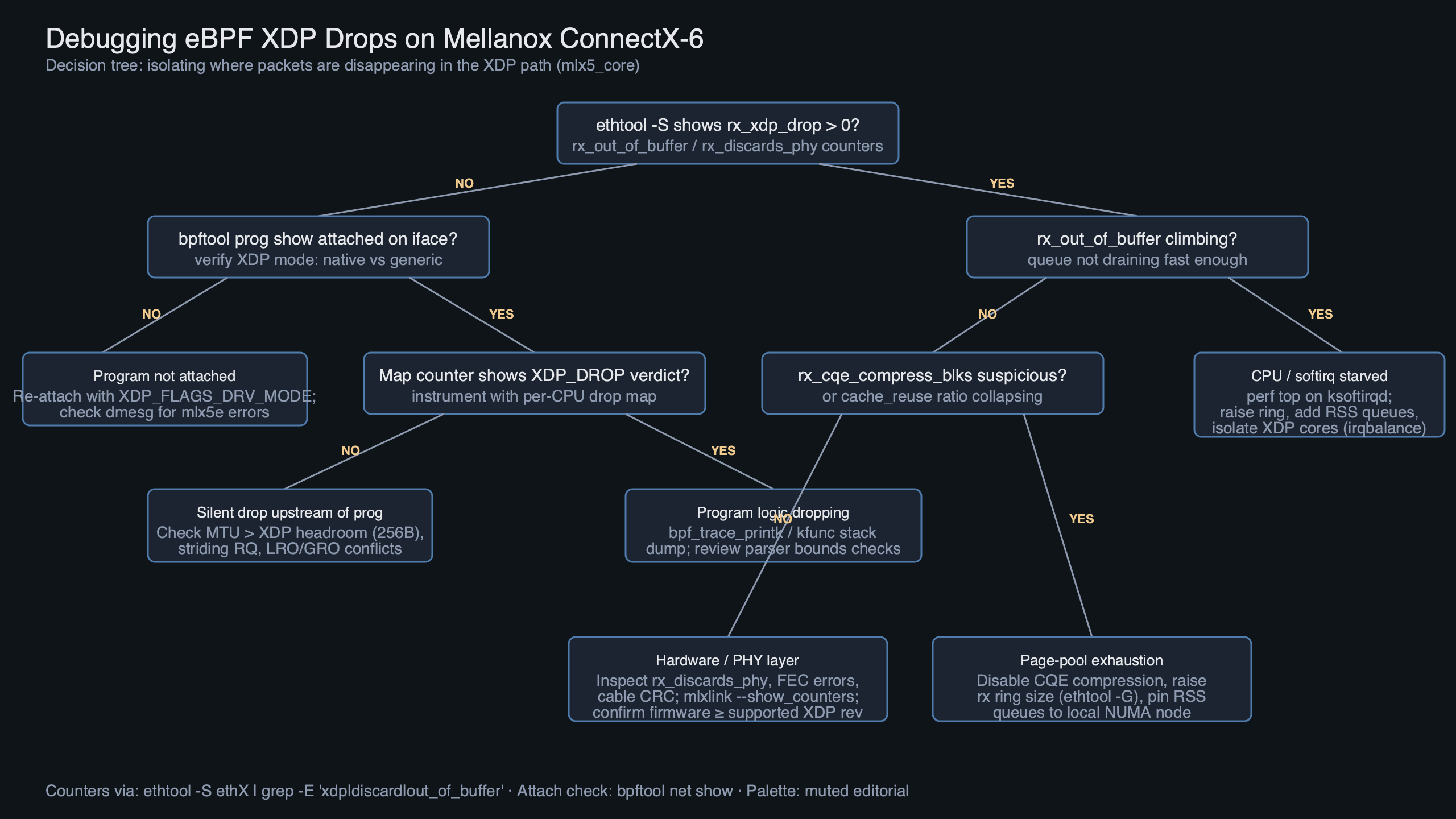
The diagram traces a packet from the ConnectX-6 receive queue, through the mlx5e page-pool allocator, into the XDP program, and onto one of four terminal paths: XDP_PASS up to the stack, XDP_TX back out the same queue, XDP_REDIRECT through a devmap or cpumap, or XDP_DROP into oblivion. The rx_xdp_drop counter sits on the drop branch — but it also increments on the far-left branch, before the program runs, if the driver cannot build a valid xdp_buff. That is the source of the ambiguity you hit in step one: the same counter covers a driver-side reject and a program-side verdict.
CQE compression and striding RQ — the subtle ones
Two mlx5-specific features interact badly with XDP and trip people up. The first is CQE compression, which packs multiple completions into a single cache line to save PCIe bandwidth. It is enabled by default on 100G+ firmware. XDP in native mode is incompatible with compressed CQEs in some firmware/driver combinations — the driver quietly disables compression when you attach a program, but if your firmware is older than 22.33.1048 you may see a stall at attach time. Check with:
ethtool --show-priv-flags enp1s0f0np0 | grep -i cqe
mstflint -d 01:00.0 q | grep FWIf rx_cqe_compress is on and firmware is below 22.33, upgrade firmware before you spend another hour on the program. NVIDIA’s mlx5 firmware changelog calls out the specific XDP + CQE compression interactions and is worth bookmarking.
The second is Striding RQ, which lets the NIC post a single large buffer and fill it with multiple packets. It is great for the non-XDP path and mandatory for some RoCE workloads, but native XDP disables it automatically and reverts to linear RQ. You can verify which mode you are in with ethtool --show-priv-flags — look for rx_striding_rq: off when XDP is attached. If it stays on after attach, you are in generic XDP, not native, and every measurement you take will be off by 3-5x on latency.
A minimal debugging checklist
When a new XDP program misbehaves on ConnectX-6, this is the sequence that catches 90% of problems in under ten minutes:
- Confirm you are in native mode:
bpftool net show dev enp1s0f0np0must showxdp/drv, notxdp/generic. - Check MTU against the page-frag ceiling. Anything above 3498 needs
xdp.fragsand kernel 6.3+. - Dump
ethtool -Sand look forrx_xdp_drop,rx_cache_full, andrx_xdp_tx_full. Non-zero values point at very different root causes. - Confirm channel count and ring depth.
ethtool -landethtool -g. Detach-reshape-reattach if you need to change either. - Attach
perf record -e xdp:xdp_exceptionto distinguish program bugs from driver rejects. - If firmware is older than 22.33, upgrade it before anything else.
The single most common root cause I see reported on the xdp-project tracker for ConnectX-6 is still the headroom/MTU mismatch — someone sets MTU 9000 expecting jumbo support, loads a program without xdp.frags, and watches rx_xdp_drop climb at line rate. The fix is thirty seconds of work once you know where to look. Everything else on this checklist is rarer but more subtle, which is exactly why you want to eliminate the obvious cases first before you start reading disassembled BPF bytecode at 3am.
Common questions
Why is rx_xdp_drop incrementing on my Mellanox ConnectX-6 even when my XDP program only returns XDP_PASS?
The rx_xdp_drop counter on mlx5_core increments in two indistinguishable cases: when the program returns XDP_DROP and when the driver cannot deliver the frame to the program at all. On ConnectX-6 this usually means a headroom miscalculation, a channel/queue mismatch after reshaping the NIC, or an RX ring too shallow to feed the page-pool that native XDP requires.
What is the maximum MTU for native XDP on ConnectX-6 without multi-buffer support?
On a 4K-page x86_64 host, native XDP on ConnectX-6 tops out at an MTU of roughly 3498 bytes because mlx5_core allocates one page per descriptor and must fit the packet plus 256 bytes of XDP_PACKET_HEADROOM and skb_shared_info padding. Jumbo frames at 9000 bytes require kernel 6.3+ and a program compiled with the xdp.frags section suffix so libbpf sets BPF_F_XDP_HAS_FRAGS.
How do I safely resize channels on a Mellanox NIC while an XDP program is attached?
Detach XDP first, reshape the channels, then re-attach. Running ethtool -L while a program is loaded leaves RSS spreading flows across hardware queues that no longer have the XDP hook, silently dropping half your traffic. The correct order is bpftool net detach xdp, then ethtool -L combined N and ethtool -G for ring depth, then bpftool net attach xdpdrv to force native mode.
What does XDP_ABORTED mean in the xdp:xdp_exception tracepoint and how do I fix it?
XDP_ABORTED means the program hit a verifier-invisible runtime error while executing, most commonly a null dereference on the return value of bpf_map_lookup_elem. You can catch it by running perf record -e xdp:xdp_exception -a -g and reading the act field in perf script. The fix is to always check the lookup return for NULL before dereferencing it, even when the key is guaranteed to exist.
References
- NVIDIA mlx5 ethtool counters reference — authoritative list of every
rx_xdp_*andrx_cache_*counter used throughout this article, including which code path increments each one. - Linux kernel commit ea5d49bdae8b — the mlx5 multi-buffer XDP support patch that enables jumbo frames with
xdp.fragsprograms, merged in 6.3. - Linux BPF redirect documentation — explains
bpf_redirect_map, devmap, and cpumap semantics thatrx_xdp_redirect_errtracks. - xdp-project/xdp-tutorial on GitHub — maintained reference for section naming conventions including
SEC("xdp.frags")and the libxdp attach API. - libbpf/bpftool on GitHub — source and docs for
bpftool net attach xdpdrv,bpftool prog profile, and the tracepoint helpers referenced in the debugging steps. - NVIDIA MLNX_OFED 24.01 release notes — documents the CQE compression and XDP firmware interactions relevant to ConnectX-6 Dx cards on firmware below 22.33.